Listlterator()
항상 next와 previous가 존재
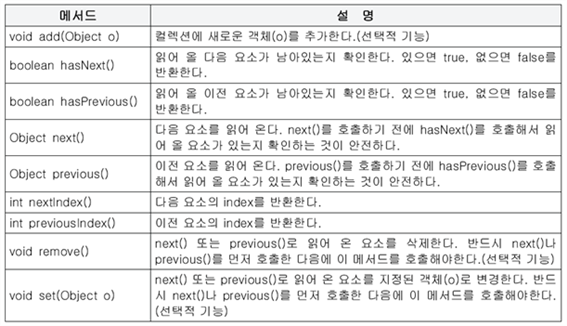
Hashset
: 해싱을 통한 집합의 개념
자료에 대한 검색 유용
해싱을 통한 집합의관리
해쉬란?
데이터 자체로부터 정보를 추출하여 정보에서 나오는 숫자를 산출
숫자와 데이터간의 연결
해싱에서 쓰이는 수 = 해싱함수
(결과값이 중복이 되지 않도록) = 충돌이 일어나지 않도록
충돌이 일어날 경우 , 하나의 번호에 여러 개를 연결되어 출력된다.
해싱에는 배열과 링크리스트 이 두 가지의 자료구조가 필요하다.
만약에 결과 값이 3으로 두 개 나왔다면 인덱스에 두 개의 링크를 연결한다.
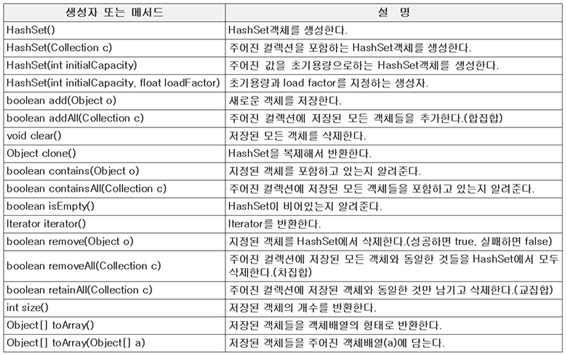
중요한 함수
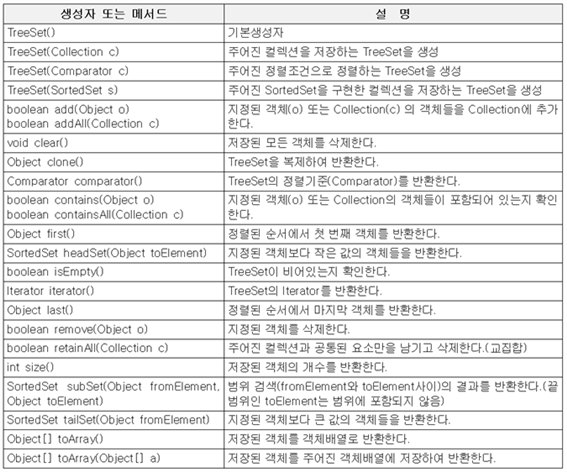
: add() clear() contains() isEmpty() iterator(순차적접근가능)
링크드리스크에는 순서가 있다. Array도 순서가 있다.
그러나 집합은 순서가 없다. 따라서 iterator()을 사용해도 순서의 의미는 없음

중복이 된다. 한번 입력이된 “abc” 다른 하나를 포용하지 않는다.
Person이라는 객체를 만들 때, 2개는 상식적으로 같은 것처럼 보이지만!
String은 중복 검열이 되지만 객체는 중복 검열을 못함
왜나면 이놈은 복합형 자료구조이기에, 자료구조 대한 해싱이 제공되지 않았기때문
따라서 총 3개의원소 출력된다.
고려사항 : 같은 것으로 취급할 수 있는 방법은?
내부에서 해쉬하는 방법을 만들어 주어야한다.
1. equals()
2. hascode()
란 매서드를 통해 재정의를 해주어야 한다.
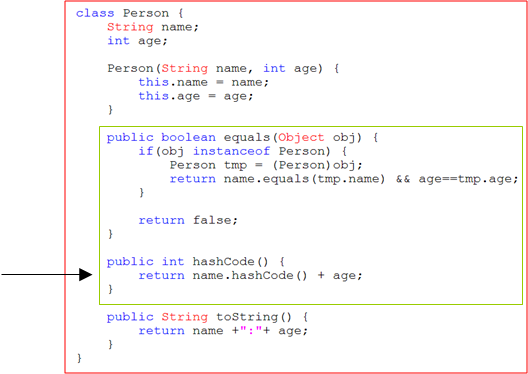
재정의한 코드
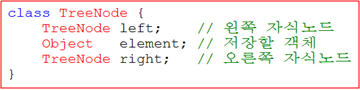
TreeSet
링크드 리스트와 같은 구조이지만 일렬형태가 아닌 트리형태
특징 ; 이진트리로서 자료구조 시간에 배웠니/
정렬이 되어있는 이진트리당
항상 노드에서부터 노드의 왼쪽은 작은 값이 배열되고 노드의 오른쪽의 자식 노드들은 큰값이 배열된다. HashSet 은 정렬의 개념이 없지만 TreeSet 은 정렬의 개념이 존재한다. 따라서 순서를 고려해야한다.
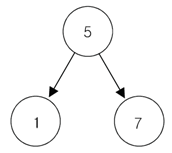
좋은 점 ; 정렬이 되어 있으니 정렬 형태로 집합이 출력된다.
이진트리는 검색하는데 매우 빠른 시간 소요
노드의 개수가 n개라면 검색은 로그n의단계로 진행
로그n은 깊이의 숫자, 깊이의 수만큼만 검색하면 검색결과를 찾을 수 있당.
대신 추가 삭제는 무진장 시간걸림 특히 삭제의 경우 후덜덜함
보통 링크드리스트나 어레이는 add()를 사용해 한단계로 수행 끝
벗 트리셋은 비교과정을 통해 저장
노드하나를 삭제할 경우, 삭제 노드만 제거한다고 되는게 아님
남은 노드들의 링크를 다시 연결시켜야함.
헤드센, 페일 셋 : 앞쪽에 있는 노드로부터 그 노드보다 작은 것들:미만(헤드셋) 큰것들:이상(테일셋)
Comparator & Comparable

Comparable : 오름차순 정렬 되어있음
HashMap
: 맵구현할 때 해쉬가 필요하다
맵은 일단 기능적으로 키와 값과의 싸움
데이터베이스에서 정보는 키를 사용
키와 데이터를 쌍으로 하여 맵핑 (해싱기법사용)
해시테이블 대신 해시맵을 쓰시오
해싱이란?
: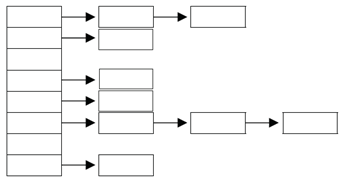 해싱의 구조
해싱의 구조
배열이 있고 각 인덱스에 연결이 되어있는 링크들로 구성
환자에대한 정보관리
간호사가 취한 방법 주민등록번호를 받아서 70년도 환자이면 캐비넷 박스에서 8번째 서랍에다 환자에 대한 정보 저장 . 90년대면 10번째 서랍에 저장 이런식
'Studynote > Computer Science 12' 카테고리의 다른 글
| [정리]Java Chapter 11 컬렉션 프레임윅과 유용한 클래스 (0) | 2018.11.05 |
|---|---|
| 11.18.제13장 AWT와 애플릿 (0) | 2018.11.05 |
| [정리]Java chapter11 컬렉션 프레임웍과 유용한 클래스 (0) | 2018.11.05 |
| [정리] Java Chapter 7 객체지향프로그래밍2 (0) | 2018.11.05 |
| [정리] Java Chapter 6 객체지향프로그래밍1 (0) | 2018.11.05 |
댓글