1. 컬렉션 프레임웍
컬렉션 프레임웍이란?
: 데이터 군을 저장하는 클래스들을 표준화한 설계
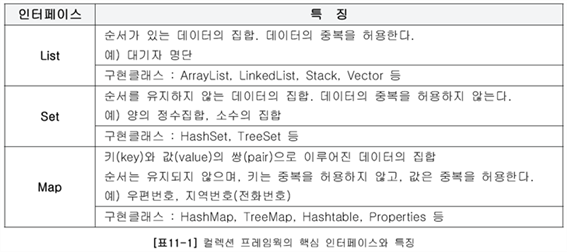
(1)컬렉션 프레임웍의 핵심 인터페이스 : List, Set, Map
컬렉션 프레임웍에서는 컬렉션을 크게 3가지 타입이 존재하다고 인식, 각 컬렉션을 다루는데 필요한 기능을 가진 3개의 인터페이스를 정의
인터페이스 List와 Set의 공통된 부분을 다시 뽑아서 새로운 인터페이스인 Collection을 추가로 정의
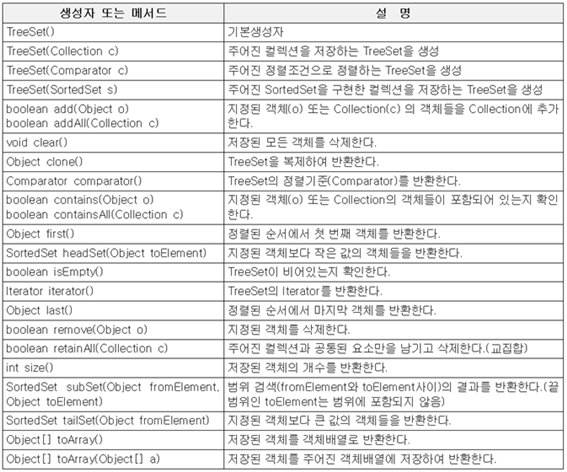
1. Collection인터페이스
Collection인터페이스는 컬렉션 클래스에 저장된 데이터를 읽고, 추가하고 삭제하는 등 컬렉션을 다루는 데 가장 기본적인 메서드를 정의
메소드 | 설 명 |
boolean add(Object) boolean addAll(Collection) | 지정된 객체(o) 또는 Collection(c) 의 객체들을 Collection에 추가한다. |
void clear() | Collection의 모든 객체를 삭제한다 |
boolean contains(Object) boolean containsAll(Collection) | 지정된 객체(o) 또는 Collection(c) 의 객체들이 Collection에 포함되어 있는지 확인한다. |
int hashCode() | Collection의 hash Code를 반환한다 |
boolean isEmpty() | Collection이 비었는지 확인한다. |
Iterator iterator() | Collection의 Iterator를 얻어서 반환하다. |
boolean remove(Object) | 지정된 객체를 삭제한다 |
boolean removeAll(Collection) | 지정된 Collection에 포함된 객체들을 삭제한다 |
boolean retainAll(Collection) | 지정된 Collection에 포함된 객체만을 남기고 다른 객체들을 Collection에서 삭제한다. 이 작업으로 인해 Collection에 변화가 있으면 true 그렇지 않으면 false를 반환한다. |
int size() | Collection에 저장된 객체의 개수를 반환한다. |
Object[] toArray() | Collection에 저장된 객체를 객체배열로 반환한다. |
Object[] toArray(Object[] a) | 지정된 배열에 Collection의 객체를 저장해서 반환한다. |
2. List인터페이스
⦁중복을 허용
⦁저장순서가 유지
- ArrayList, LinkedList, Vector, Stack
3. Set인터페이스
⦁중복 허용x
⦁저장순서가 유지 x
-HashSet, TreeSet
4. Map인터페이스
⦁키와 값을 하나의 쌍으로 묶어서 저장
⦁키는 중복x, 값은 중복 허용
⦁기존에 저장된 데이터와 중복된 키와 값을 저장하면 기존의 값은 없어지고 마지막에 저장된 값이 남음
- Hashtable, HashMap, LinkedHashMap, SortedMap, TreeMap
5. Map,Entry
⦁Map인터페이스의 내부 인터페이스
-내부인터페이스?
: 내부클래스처럼 인터페이스도 인터페이스 안에 인터페이스를 정의하는 내부 인터페이스를 정의 할 수 있음
Map에 저장되는 키-값 쌍을 다루기 위해 내부적으로 Entry인터페이스를 정의해 놓음
![]()
(2) 동기화
멜티쓰레드 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근 가능
→ 데이터의 일관성을 유지하기 위해 동기화 필요
구버전의 클래스의 경우 자체적 동기화처리가 되어있음 : 불필요한 기능으로 성능저하 유발
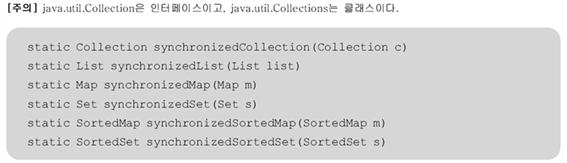
따라서 신버전의 클래스의 경우 필요한 경우 java.util.Collection클래스의 동기화 메서드를 이용해서 동기화 처리
코드상 구현은

![]()
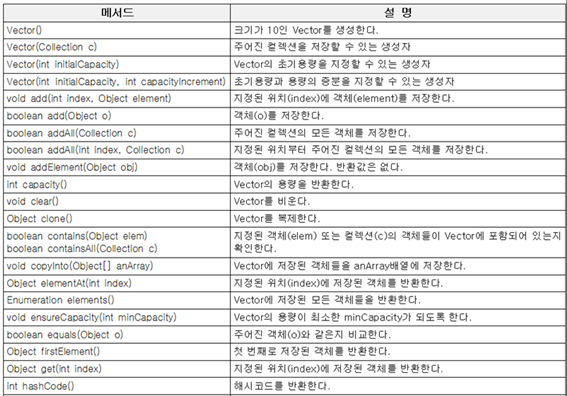
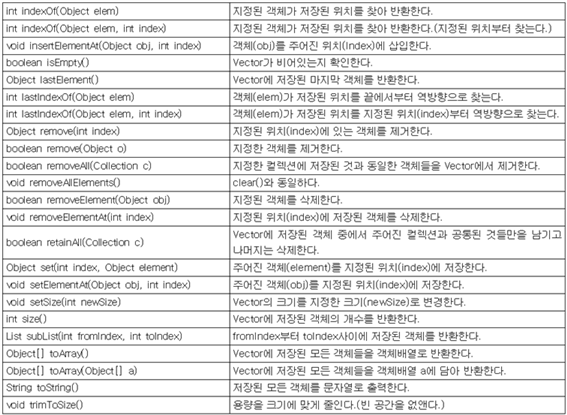
(3) Vector와 ArrayList
공통점 | -List인터페이스를 구현(저장순서유지, 중복허용) -데이터의 저장공간으로 배열 사용 |
차이점 | -vector는 멀티쓰레드에 대한 동기화가 되어있으나 ArrayList는 그렇지 않다. |
-Object배열을 이용해서 데이터를 순차적으로 저장 (인덱스의 개념은 c와 동일)

⦁protected : 상속시 자손클래스에서 접근이 가능하도록 하기 위해
⦁Object : 모든 종류의 객체를 포함할 수 있다
⦁ elementData[]; : 맴버변수
-ArrayList는 removeRange()를 제외한 모든 메서드가 Vector의 메서드와 일치
<ArrayList 예제>
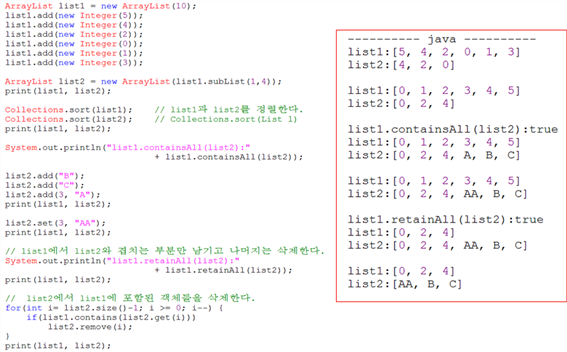
⦁for문을 이용한 list1과 list2의 공통 요소 삭제 : list2.size()-1부터 감소하는 방식
Why? 카운터를 증가하면서 삭제할 경우, 삭제될 때마다 빈공간을 채우기위해 자리이동을 해야 한다. 따라서 편리성과 효율성을 위해 감소하는 방식을 선택
Vector의 크기와 용량

위의 코드의 과정을 그림으로 보면,
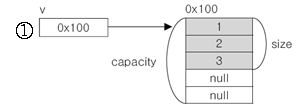
- capacity가 5인 vector인스턴스 v를 생성하고 3객의 객체를 저장
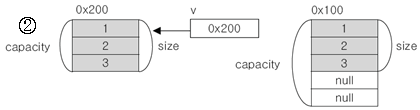
- v.trimToSize()를 호출시, v의 빈공간을 없애서 size와 capacity를 같게한다.
배열은 크기를 변경할 수 없기 때문에 새로운 배열을 생성해서 그 주소값을 변수 v에 할당
기본의 Vector인스턴스는 더 이상 사용불가 → 카비지컬레터에 의해 메모리에서 제거
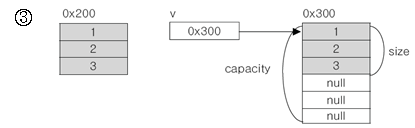
- v.ensureCapacoty(6)는 v의 capacity가 최소한 6이 되도록 한다.
만일 v의 capacity가 6이상이라면 아무일도 일어나지 않는다.
이 역시 기존 인스턴스가 아닌 새로운 인스턴스를 생성하였다.
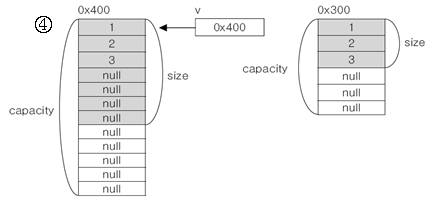
- v.setSize(7)는 v의 사이즈가 7이 되도록 한다.
만일 v의 capacity가 충분하면 새로 인스턴스를 생성할 필요 없다.
Vector는 capacity가 부족할 경우 기존의 크기보다 2배의 크기로 증가된다.
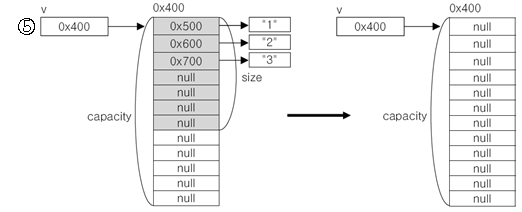
-v.clear()로 v의 모든 요소 삭제
⟹ 배열을 이용한 자료구조는 용량을 변경해야 할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야하기에 처음에 인스턴스 생성 시, 저장할 데이터의 개수를 잘 고려하여 충분한 용량의 인스턴스를 생성하는 것이 좋다.
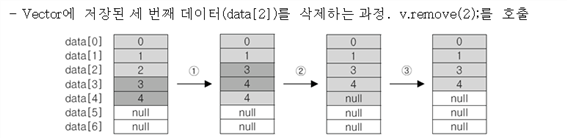
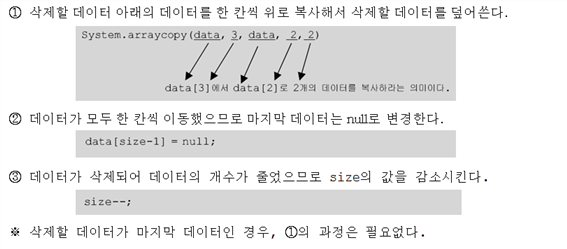
Vector의 객체 삭제
Deep Copy & Shallow Copy
Deep Copy
⦁깊은 복사
⦁원본과 같은 데이터를 저장하고 있는 새로운 객체나 배열을 생성
⦁원본 의 데이터가 바뀌다 할지라도 복사본은 완전히 독립적인 객체이므로 전혀 영향을 받지 않는다.
public Object[] toArray() { Object[] result = new Object[size]; System.arraycopy(data,0,result,0,size);
return result; } |
Shallow Copy
⦁얕은 복사
⦁단수히 참조만 복사하는 것
⦁원본이 변경되면 복사본도 같이 변경
public Object[] toArray { return data; } |
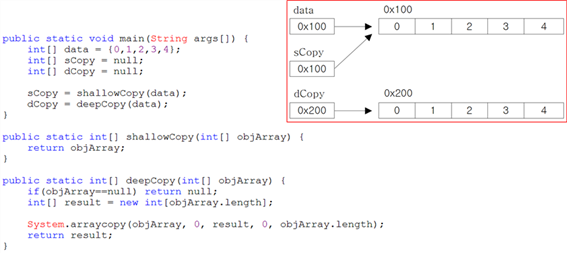
![]()
(4) LinkedList
배열의 장단점 | |
장점 | 가장 기본적인 형태의 자료구조, 간단한 구조, 쉬운 사용, 데이터를 읽어오는 시간이 가장 빠름 |
단점 | 1. 크기를 변경할 수 없다. 2. 비순차적인 데이터 추가 또는 삭제에 시간이 많이 걸린다. |
이런 단점 보완을 위해 LinkedList 개발
■ 링크드리스트
링크드리스트는 불연속적으로 존재&데이터를 서로 연결한 형태로 구성
링크드리스트 노드의 기본구성 |
class Node { Node next; //다음요소의 주소를 저장 Object obj; // 데이터를 저장 } |

⦁링크드리스트의 삭제
삭제하고자 하는 요소의 이전요소가, 삭제하고자 하는 요소의 다음요소를 참조하도록 변경 단, 하나의 참조만 변경하면 삭제가 이루어짐
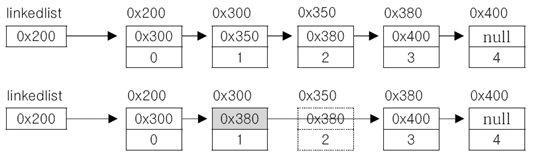
⦁링크드리스트의 추가
새로운 요소 생성, 추가하고자하는 위치의 이전 요소의 참조를 새로운 요소에 대한 참조로 변경, 새로운 요소가 그 다음 요소를 참조하도록 변경
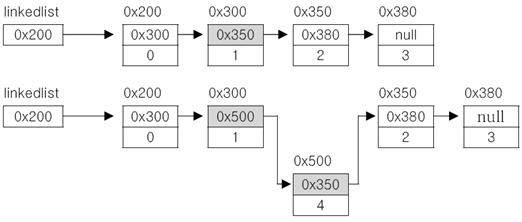
■ 더블 링크드리스트
⦁링크드리스트는 이동방향이 단방향이게 이전요소에 대한 접근이 어려움
⦁단순히 링크드리스트에 참조변수를 하나 더 추가하여 다음요소에 대한 참조뿐 아니라 이전 요소에 대한 참조가 가능하도록 함
더블 링크드리스트 노드의 기본 구성 |
class Node { Node next; //다음요소의 주소를 저장 Node previous; // 이전요소의 주소를 저장 Object obj; // 데이터를 저장 } |

■더블 써큘러 링크드리스트
⦁더블 링크드리스트의 첫 번째 요소와 마지막 요소를 서로 연결
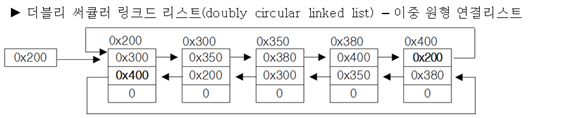
⟹ 배열 < 링크드리스트 < 더블 링크드리스트 < 더블 써큘러 링크드리스트
LinkedList 클래스
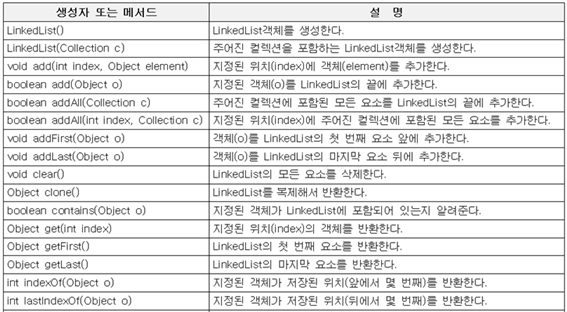
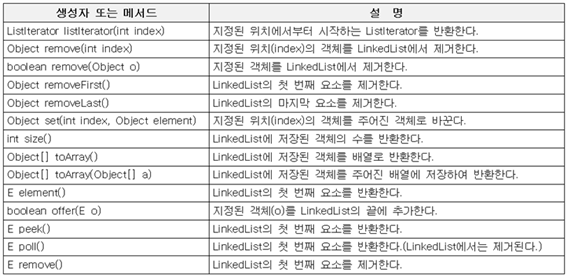
LinkedList도 List인터페이스를 구현했기에 ArrayList와 유사
그러나 이 두 클래스를 비교해보자면,
⦁순차적으로 추가/삭제하는 경우 ArrayList가 더 빠르다
⦁중간 데이터를 추가/삭제하는 경우 LinkedList가 더 빠르다.
⦁접근시간은 ArrayList가 더 빠르다.
배열의 경우, n번째 원소의 값을 얻어오려면
n번째 데이터의 주소 = 배열의 주소+n*데이터 타입의 크기 |
![]()
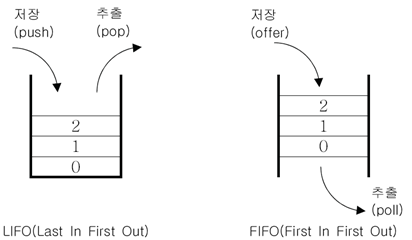
(5)Stack과 Queue
스택
⦁LIFO : 마지막에 저장한 데이터를 가장 먼저 꺼낸다
⦁동전통 구조
⦁ArrayList와 같은 배열기반 컬렉션이 적함
큐
⦁FIFO : 처음에 저장한 데이터를 가장 먼저 꺼낸다.
⦁파이프 구조
⦁LinkList로 구현하는 것이 적합
![]()
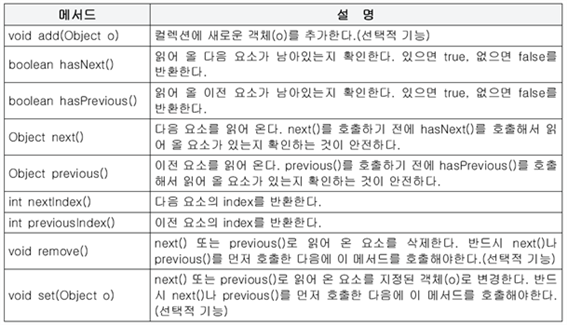
(6) Enumeration, Iterator, Listlterator
컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스
1. Iterator
⦁컬렉션 프레임웍은 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화

⦁컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator인터페이스를 정의, Collection인터페이스에는 Iterator를 반환하는 iterator()를 정의
public interface Iterator { boolean hasNext(); Object next(); void remove(); }
public interface Collection { ... public Iterator iterator(); ... } |
⦁iterator()는 Collection인터페이스의 자손인 List,Set에도 포함

- List클래스는 저장순서를 유지
- Set클래스는 저장순서 유지 안함
⦁Iterator와 같은 공통 인터페이스를 정의해서 표준을 정의하고 구현하여 따르는 것은 코드의 일관성을 유지하고 재사용성을 극대화하기에 긍정적!
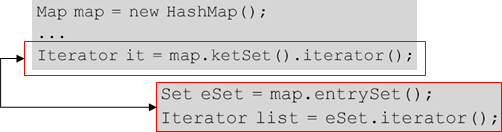
⦁Map인터페이스를 구현한 컬렉션 클래스는 키와 값을 쌍으로 저장하기에 keySet()이나 entrySet()과 같은 메서드를 통해서 키와 값을 각각 따로 Set의 형태로 얻어 온 후에 다시 iterator()를 호풀해야 Iterator를 얻을 수 있다.
2. Enumeration과 ListLterator
Enumeration : Iterator의 구버전
ListIterator : Iterator를 상속받아 기능 추가, 양방향으로 이동가능,List인터페이스 구현 컬렉션만 사용가능
(7)HashSet
⦁Set인터페이스를 구현한 가장 대표적인 컬렉션
⦁중복요소를 저장하지 않는다 → add()나 addAll()메서드 구현시 중복요소가 있는지 확인 후, 없을 경우 추가된다.
⦁저장순서를 유지하고 싶을 경우,LinkedHashSet 사용
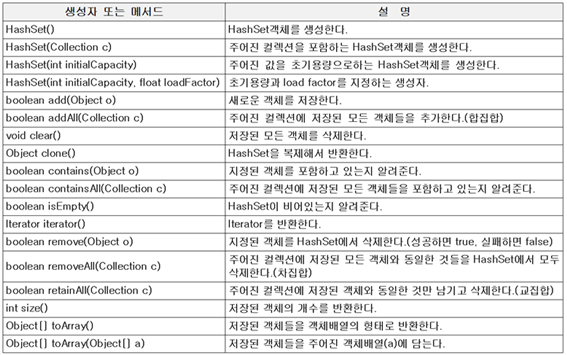
HashSet의 add메서드는 새로운 요소를 추가하기 전에 기존에 저장된 요소와 같은 것인지 판별하기 위해 추가하려는 요소의 equals()와 hashCode()를 호출하기 때문에 equals()와 hashCode()의 목적에 맞게 오버라이딩해야한다.
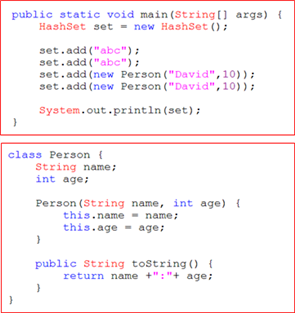
⦁이름과 나이가 같으면 같은 사람으로 인식되어야하는데 결과 값을 보면 두 인스턴스의 이름과 나이가 같더라도 서로 다른 것으로 인식한다.
→ Solution : 오버라이딩!
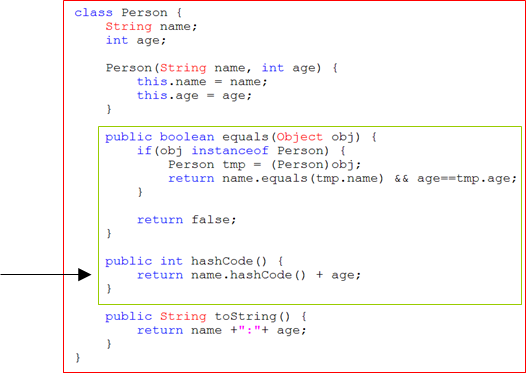
⦁Person2클래스에서 두 인스턴스의 이름과 나이가 서로 같은 true를 반환하도록 equals()를 오버라이딩하였다.
⦁hashCode()는 String클래스의 hashCode()를 이용해 구현
⦁오버라이딩을 통해 작성된 hashCode()메서드는 세가지 조건을 만족해야한다
1. 동일한 객체에 대해 여러 번 hashCod()를 호출해도 동일한 int값을 반환해야한다.

⦁ hashCode1과 hashCode2의 값을 항상 일치해야함
⦁hashCode3의 경우 맴버변수의 값이 변경되었기에 이에 관계없다
2.equals()메서드를 이용한 비교에 의해서 true를 얻은 두 객체에 대해 각각 hashCode()를 호출해서 얻은 결과는 반드시 같아야 한다.

⦁p1과 p2에 대해서 equals()메서드를 이용한 비교의 결과인 변수 b가 true라면, hashCode1과 hashCode2가 같아야한다.
3.equals()메서드로 호출했을 때 false를 반환하는 두객체는 hashCode() 호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮지만, 해싱을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 int값을 반환하는 것이 좋당
(8)TreeSet
⦁이진검색트리를 이용한 데이터를 저장하는 컬렉션 클래스
⦁정렬,검색,범위검색에 뛰어남
⦁TreeSet의 경우 이진검색트리의 성능을 향상시킨 레드-블랙 트리로 구현
⦁Set인터페이스를 구현 : 중복저장 안함 , 저장순서 유지 안함
■이진트리
: 여러 개의 노드가 서로 연결된 구조
각 노드에 최대 2개의 노드를 연결할 수 있음
루트라고 불리는 하나의 노드에서부터 시작해서 계속 확장해나감
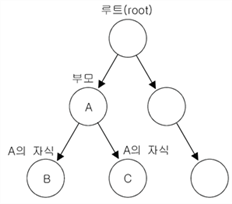
이진트리의 노드 |
class TreeNode { TreeNode left; //왼쪽 자식노드 Object element; // 객체를 저장하기 위한 참조변수 TreeNode right; //오른쪽 자식노드 } |
■이진검색트리
: 부모노드의 왼쪽에는 부모노드의 값보다 작은 값의 자식노드를,
오르쪽에는 큰값의 자식노드를 저장하는 이진트리
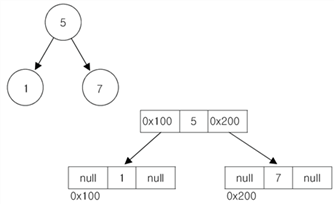
⦁트리는 순차적으로 저장이 되지 않기에 노드의 추가 삭제에 시간이 걸린지만, 검색과 정렬에 유리하다.
⦁범위 검색 : subSet()을 이용
System.out.println("result1 : " +set.subSet(from,to); //String from = "b"; //String to = "d"; |
result1 : [bat, car] |
시작범위는 포함되지만 끝 범위는 포함되지 않는다.
만약 끝범위(d)로 시작하는 단어도 포함하려면,끝 범위에 'zzz'와 같은 문자열을 붙여라
System.out.println("result2 : " +set.subSet(from,to+"zzz")); |
result2 : [bat, car, dZZZ, dance, disc] |
- dZZZ가 dance보다 앞에 정렬된 이유 : 대문자가 소문자보다 우선하기에
→대소문자가 섞이면 다른 범위검색결과을 얻기에 하나로 통일하는 것이 좋다
⦁문자열의 경우
오름차순 정렬 : 코드값의 크기가 작은 순에서 큰순으로, 공백-숫자-대문자-소문자 순
내림차순 정렬 : 이 반대
(9)Comparator와 Comparable
⦁객체를 정렬함에 있어 필요한 메서드를 정의

- Comparable의 경우 ,같은 타입의 인스턴스끼리 서로 비교가능한 클래스, 오름차순,정렬가능

⦁compareTo() : 반환값 int, 두 객체가 같으면 0, 비교값보다 작으면 음수, 크면 양수 반환
⦁compare() : 객체를 비교해서 음수,0,양수 중 하나를 반환하도록 구현
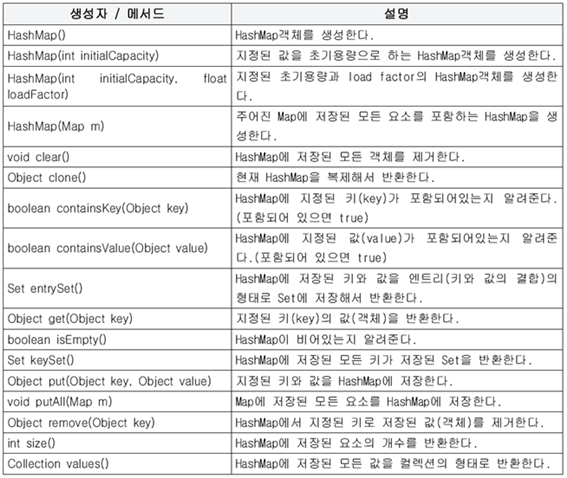
(10)Hastable과 HashMap
⦁Hastable < HashMap
⦁Map인터페이스를 구현
-키와 값을 묶어서 하나의 데이터로 저장함
-해싱을 사용 → 다량의 데이터를 검색하는데 뛰어남
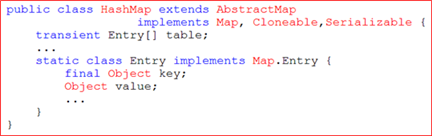
⦁Entry라는 내부클래스를 정의하여 키와 값을 하나의 클래스로 정의
⦁이를 하나의 Entry타입의 배열로 선언하여 사용
→ 데이터의 무결성적 측면에서 효율적
⦁HashMap은 키와 값을 Object타입으로 저장 → 어떤 객체도 저장가능

⦁HashMap에 저장된 데이터를 하나의 키로 검색했을 때 결과가 단 하나이여야 한다.
ex. ID를 키로 비밀번호를 값으로 연결한 데이터집합이 있다고 가정
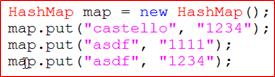
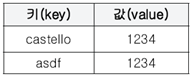
⦁HashMap을 생성하고 데이터를 저장하는 코드
⦁3개의 데이터 쌍을 저장했지만 실제로 2개만 저장된 이유 → 중복된 키가 존재
⦁entrtSet()를 이용해 키와 값을 함께 읽을 수도 있고, keySet()이나 values()를 이용해서 키와 값을 따로 읽을 수 도 있다.
⦁HashMap은 데이터를 키와 값을 모두 Object타입으로 저장하기 때문에 HashMap의 값으로 HashMap을 다시 저장할 수 있다. → 하나의 키에 다시 복수의 데이터를 저장
ex.전화번호부 구현 코드에서 그룹을 만들고, 그룹안에 다시 이름과 전화번호를 저장
⦁문자열 배열에 담긴 문자열을 하나씩 읽어서 HashMap에 키로 저장, 값을 1로 저장
containKeys()로 확인하여 이미 저장되어 있는 문자열이면 값을 1증가
pritBar()를 이용해 그 결과를 그래프로 표현
→ 문자열 배열에 담기 문자열들의 빈도수를 구할 수 있다
■해싱
⦁해시함수를 이용해서 데이터를 해시테이블에 저장하고 검색하는 기법
⦁배열과 링크드리스트의 조함
⦁저장할 데이터의 키를 해시함수에 저장, 배열의 한요소로 인식, 다시 그곳에 연결되어있는 링크드리스트에 저장
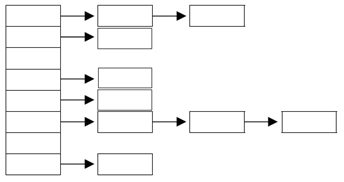
⦁키를 이용하여 해시테이블로부터 데이터 가져오기
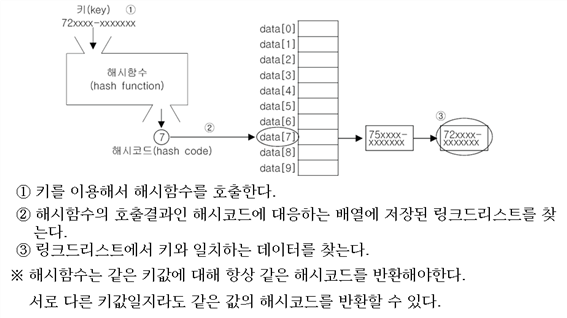
⦁하나의 링크드리스트에 많은 데이터가 저장된 형태 < 많은 링크트리스트에 하나의 데이터만 저장된 형태 : 더 빠른 검색결과을 얻어옴
⦁Object에 정의된 hashCode()를 해시함수로 사용하여 해시코드를 얻는 것이 중복없이 해시코드를 얻는 최적의 방법
⦁서로 다른 두객체에 대해 equals()로 비교한 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식(객체구별법)
⦁이미 존재하는 키에 대한 값을 저장하면 새로운 값으로 덮어씌여진다.
→ 새로운 클래스 정의시, equals()를 오라이딩해야한다면 hashCode()도 재정의해서 두 값을 결과가 항상 같도록 해야함
(11)TreeMap
⦁이진검색트리의 형태
⦁키와 값의 싸으로 이루어진 데이터를 저장
⦁검색과 정렬에 적합 (정렬시 오름차순이 기본)
⦁검색의 경우 HashMap이, 범위검색이나 정렬의 경우 TreeMap이 더 유용
(12)Properties
⦁HashTable을 상속받아 구현
⦁키와 값을 (String, String)의 형태로 저장하는 단순한 컬렉션 클래스
⦁어플리케이션의 환경설정과 관련된 속성을 저장하는데 사용
⦁데이터를 파일로부터 일고 쓰는 편리한 기능 제공
⦁간단한 입출력에 주로 사용
- setProperty() : 단순히 HashTable의 put메서드를 호출, 기존에 같은 키로 저장된 값이 있는 경우 그 값을 Object타입으로 반환 else null 반환
- getProperty() : Properties에 저장된 값을 읽어오는 일, 일어오려는 키가 존재하지 않을 경우 지정된 기본값을 반환
⦁출력순서와 저장순서는 무관
⦁Enumeration사용
⦁list메서드를 이용해 모든 데이터를 화면 또는 파일에 편리하게 출력
⦁외부파일(imput.txt)로부터 데이터를 입력받아 출력가능
⦁store() storeToXML를 이용해서 파일로 저장 가능
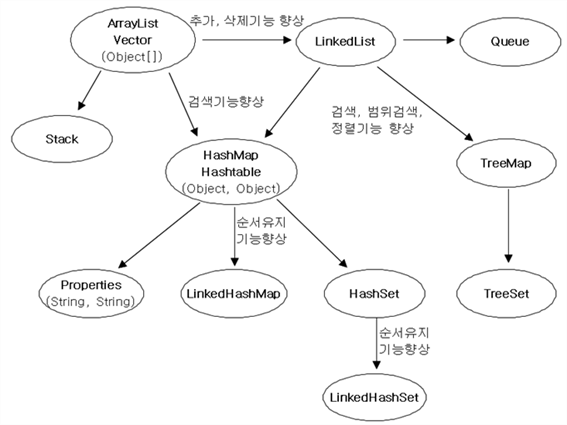
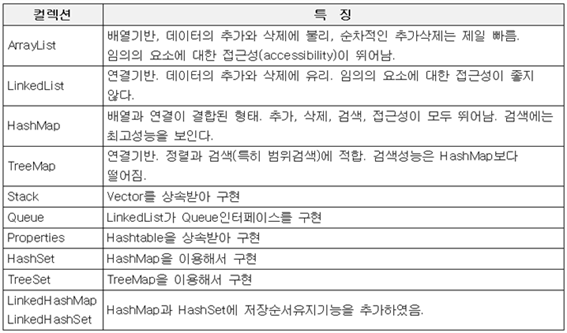
(13)컬렉션 클래스 정리 & 요약
'Studynote > Computer Science 12' 카테고리의 다른 글
| [14.09.15.Mon] 시스템프로그래밍 (0) | 2018.11.05 |
|---|---|
| [정리]Java Chapter 13 AWT와 애플릿 (0) | 2018.11.05 |
| 11.18.제13장 AWT와 애플릿 (0) | 2018.11.05 |
| 11.11.제11장 컬렉션 프레임윅과 유용한 클래스 (0) | 2018.11.05 |
| [정리]Java chapter11 컬렉션 프레임웍과 유용한 클래스 (0) | 2018.11.05 |
댓글